Stratified sampling duomenų dalijime: kaip užtikrinti teisingą klasių pasiskirstymą
Sužinokite, kas yra stratified sampling duomenų dalijime, kodėl jis būtinas mašininio mokymosi modeliams ir kaip teisingai taikyti šį metodą praktikoje.
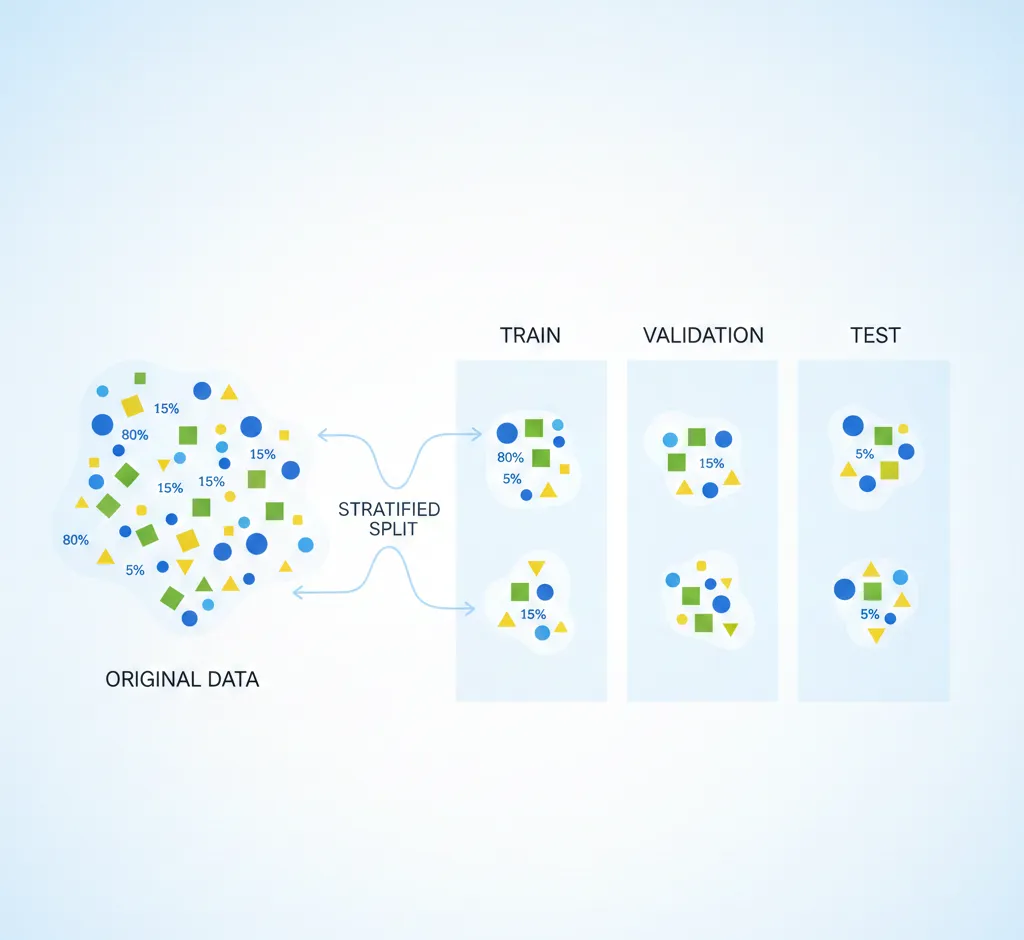
Stratified sampling (stratifikuota atranka) – tai vienas svarbiausių metodų, kai kalbama apie teisingą duomenų dalijimą į treniravimo, validacijos ir testavimo rinkinius tiek statistikoje, tiek mašininio mokymosi projektuose. Šis metodas padeda išlaikyti realų klasių ar kitų reikšmingų požymių pasiskirstymą visuose rinkiniuose, taip sumažinant riziką išmokyti modelį iškreiptais ar ne atstovaujančiais duomenimis.
Kas yra stratified sampling?
Stratified sampling esmė – visą populiaciją ar duomenų aibę padalinti į homogeniškas pogrupius (stratas) pagal tam tikrą požymį ir tik tuomet atsitiktinai imti imtį iš kiekvienos stratos taip, kad bendra imtis atspindėtų pradinę struktūrą. Dažniausiai toks požymis yra tikslinė klasė klasifikavimo užduotyse (pvz., „teigiama / neigiama“, „spam / ne spam“, skirtingos ligų klasės ir pan.).
Skirtingai nei paprastas atsitiktinis dalijimas, kuris tikisi, kad didelė imtis savaime atkartos populiacijos pasiskirstymą, stratifikuotas dalijimas priverstinai užtikrina, kad kiekviena klasė ar grupė bus reprezentuojama proporcingai. Tai ypač svarbu, kai duomenys nėra tolygūs ir kai kurios klasės yra retos.
Kodėl stratified sampling reikalingas duomenų dalijime?
Dalijant duomenis į treniravimo ir testavimo rinkinius be stratifikacijos, galima labai iškreipti klasių pasiskirstymą. Pavyzdžiui, jei iš viso turite tik 5 % teigiamos klasės pavyzdžių, paprastas atsitiktinis dalijimas gali lemti, kad testavimo rinkinyje tokių pavyzdžių išvis nebeliks. Tuomet modelis atrodys labai tikslus, nors realybėje jis nieko neišmoko apie retą, bet svarbią klasę.
- Teisingas modelio vertinimas. Išlaikydami vienodą klasių proporciją treniravimo ir testavimo rinkiniuose, galite sąžiningai palyginti modelio rezultatus su realia situacija.
- Stabilesni metrikų rezultatai. Tokios metrikos kaip tikslumas, F1, ROC AUC ar balansuotas tikslumas tampa patikimesnės, nes nėra iškreiptos atsitiktiniais imties šuoliais.
- Mažesnė atsitiktinių svyravimų įtaka. Ypač mažų duomenų rinkinių atveju stratifikacija padeda išvengti situacijos, kai vienoje imtyje klasė išvis nepatenka.
Stratified sampling ir klasifikavimo užduotys
Dažniausiai stratified sampling taikomas klasifikavimo užduotyse, nes čia ypač svarbus tikslinės klasės pasiskirstymas. Klasės, kurių duomenyse yra mažai, dažnai būna būtent tos, kurios turi didelę verslo ar tyrimų vertę: sukčiavimas, defektai, retos ligos, nutraukti klientai ir t. t.
Su stratifikuota atranka užtikrinama, kad:
- kiekvienoje klasėje esantys pavyzdžiai bus atstovaujami ir treniravimo, ir testavimo rinkiniuose;
- modelis „matys“ reprezentatyvią visų klasių kombinaciją mokymosi metu;
- vertinimo metu gausite realesnį vaizdą, kaip modelis elgsis su retais, bet itin svarbiais atvejais.
Kaip veikia stratified sampling žingsnis po žingsnio?
Stratifikuota atranka turi gana aiškią logiką, kurią lengva suprasti ir rankiniu būdu, ir naudojant bibliotekas (pvz., scikit-learn). Žemiau pateikiamas bendras veikimo algoritmas.
- Pasirinkite stratifikavimo požymį. Dažniausiai tai yra tikslinė kintamoji (label), bet gali būti ir kitas svarbus požymis – pavyzdžiui, vartotojo tipas, regionas, amžiaus grupė.
- Suskaidykite duomenis į stratas. Visi įrašai, atitinkantys tą pačią klasę ar grupę, sudaro vieną stratą. Pavyzdžiui, visi „teigiami“ pavyzdžiai – viena strata, visi „neigiami“ – kita.
- Nustatykite pageidaujamas proporcijas. Nusprendžiama, kokia dalis visų duomenų bus skirta treniravimui, validacijai ir testavimui (pvz., 70/15/15 arba 80/20).
- Atsitiktinai parinkite įrašus kiekvienoje stratoje. Iš kiekvienos stratos pagal nustatytas proporcijas atsitiktinai parenkami įrašai treniravimo, validacijos ir testavimo rinkiniams.
- Sujunkite visų stratų dalis. Sujungus atrinktus įrašus iš visų stratų gaunami galutiniai rinkiniai, kuriuose išlaikytas bendras klasių pasiskirstymas.
Proporcingas ir disproporcingas stratified sampling
Yra du pagrindiniai stratifikuotos atrankos tipai, kurie dažnai naudojami praktikoje: proporcingas ir disproporcingas (arba subalansuotas).
Proporcingas stratified sampling
Proporcingas stratified sampling reiškia, kad iš kiekvienos stratos paimama tiek įrašų, kad imtyje klasių pasiskirstymas sutaptų su pirminio duomenų rinkinio proporcijomis. Jei pradiniuose duomenyse 90 % įrašų priklauso „neigiamos“ klasės grupei ir 10 % – „teigiamos“, treniravimo ir testavimo rinkiniuose šios proporcijos išliks tokios pačios.
- Šis būdas idealiai tinka, kai norite sąžiningai atspindėti realų pasaulį ir nekoreguoti klasių disbalanso.
- Rezultatai būna tinkami daugumai vertinimo metrikų ir padeda geriau suprasti realų modelio elgesį.
Disproporcingas stratified sampling
Disproporcingas stratified sampling taikomas tada, kai sąmoningai nusprendžiama keisti klasių proporcijas imtyje, dažniausiai siekiant padidinti retos klasės dalį. Pavyzdžiui, jei realybėje turite 1 % sukčiavimo atvejų, galite suformuoti treniravimo imtį, kurioje būtų 10–20 % tokių atvejų.
- Tokiu būdu modelis turi daugiau pavyzdžių, iš kurių gali mokytis atpažinti retus, bet svarbius reiškinius.
- Treniravimo rinkinyje balansuojamos klasės, tačiau vertinimui vis tiek rekomenduojama naudoti rinkinius su realiomis proporcijomis.
- Šis metodas artimai susijęs su oversampling ir undersampling technikomis, tačiau čia pagrindinis akcentas – tinkamai atrinkti pavyzdžiai iš stratų.
Stratified sampling ir train/validation/test split
Praktikoje stratified sampling dažniausiai taikomas ne tik tarp treniravimo ir testavimo rinkinių, bet ir dalijant duomenis į train/validation/test. Taip išvengiama situacijos, kai, pavyzdžiui, validacijos rinkinyje nesulaukiama tam tikrų klasių arba jos būna pernelyg sumenkintos.
Tipinė schema gali atrodyti taip:
- Pirmiausia visą duomenų rinkinį stratifikuotai padalijate į treniravimo (pvz., 80 %) ir testavimo (20 %) rinkinius.
- Tuomet treniravimo rinkinį vėl stratifikuojate ir dalijate į naują treniravimo (pvz., 70 %) ir validacijos (30 %) dalis.
- Visuose žingsniuose užtikrinama, kad klasių ar kitų pasirinkto požymio proporcijų iškraipymas būtų minimalus.
Kada stratified sampling ypač būtinas?
Nors teoriškai stratified sampling naudingas beveik visada, yra situacijų, kuriose jo nenaudoti būtų rimta klaida. Štai dažniausios:
- Labai disbalansuotos klasės. Jei viena klasė sudaro mažiau nei 10–20 % visų įrašų, nestratifikuotas dalijimas gali ją beveik visiškai „prarasti“ testavimo rinkinyje.
- Maži duomenų rinkiniai. Kai bendra įrašų suma nedidelė, atsitiktiniai svyravimai turi daug didesnę įtaką, todėl stratifikacija tampa būtina.
- Retos, bet verslo požiūriu kritiškos klasės. Pavyzdžiui, sukčiavimas, defektai gamyboje, saugumo incidentai – jei jų nepristatysite į treniravimo ir testavimo rinkinius, modelis taps praktiškai nenaudingas.
Ką galima naudoti kaip stratifikavimo požymį?
Nors dažniausiai pasirenkama tikslinė klasė, kartais verta stratifikaciją atlikti pagal kitus požymius. Ypač tada, kai tikslinę kintamąją turite tik daliai duomenų arba kai norite užtikrinti teisingą pasiskirstymą pagal kelis kriterijus.
- Regionas ar rinka. Jei jūsų duomenys apima kelias šalis ar miestus, gali būti svarbu, kad kiekviena geografija būtų reprezentuota visose imtyse.
- Laiko periodas. Laiko eilučių užduotyse kartais norima, kad skirtingi laikotarpiai (pvz., sezonai) turėtų savo atstovus treniravimo ir testavimo rinkiniuose.
- Vartotojo tipas. Nemokami / mokami klientai, nauji / lojalūs vartotojai ir pan. – tai dažni požymiai, pagal kuriuos norima subalansuoti imtis.
Stratified sampling ribojimai ir kada jo vengti
Nors stratified sampling turi daug privalumų, tai nėra panacėja. Yra keletas situacijų, kuriose šis metodas arba neprideda vertės, arba netgi gali pakenkti rezultatams, jei taikomas neapgalvotai.
- Nuolatinės regresijos užduotys. Jei prognozuojate ne klasę, o tęstinę reikšmę (pvz., kainą), paprasta stratifikacija pagal tikslinę kintamąją gali būti sudėtinga. Tokiu atveju kartais taikomas „binning“ – tikslinė reikšmė padalijama į intervalus ir naudojama kaip pseudo-klasė.
- Labai daug smulkių klasių. Kai klasių labai daug ir dalis jų yra beveik tuščios, stratifikacija gali tapti techniškai sudėtinga ir lėta, o dalyje rinkinių vis tiek liks labai mažai pavyzdžių.
- Laiko eilučių dalijimas. Jei esminis reikalavimas – nepažeisti chronologinės sekos, pirmiausia turi būti gerbiamas laiko nuoseklumas, o tik vėliau galima svarstyti ribotą stratifikaciją.
Praktiniai patarimai taikant stratified sampling
Norint, kad stratified sampling būtų maksimaliai naudingas, svarbu atsižvelgti į kelias praktines rekomendacijas. Tai padės išvengti klaidų ir užtikrinti, kad jūsų treniravimo ir testavimo rinkiniai iš tiesų bus reprezentatyvūs.
- Prieš dalijant, išanalizuokite klasių pasiskirstymą. Vizualizacijos ir paprastos lentelės padės pamatyti, ar egzistuoja rimtas disbalansas, bei nuspręsti, ar reikia papildomų balansavimo žingsnių.
- Užfiksuokite atsitiktinumo sėklą. Nustatę „random_state“ arba lygiavertį parametrą, užtikrinsite, kad skirtinguose paleidimuose gausite tuos pačius rinkinius ir galėsite atsekti rezultatus.
- Naudokite tą pačią stratifikavimo logiką visiems splitams. Jei dalijate į train/validation/test, pasirūpinkite, kad visų žingsnių metu būtų naudojamas tas pats stratifikavimo požymis.
- Stratifikuokite tik pagal stabilų požymį. Venkite kintamųjų, kurių reikšmės stipriai kinta laike ar kuriuos vėliau planuojate transformuoti taip, kad jie prarastų savo pradines reikšmes.
Stratified sampling ir modelių palyginimas
Kai lyginate skirtingus mašininio mokymosi modelius ar skirtingas hiperparametrų konfigūracijas, būtina užtikrinti, kad visi jie būtų treniruojami ir testuojami ant identiškų duomenų rinkinių. Stratified sampling čia tampa savotišku „standartu“, pagal kurį sukuriamas bendrai naudojamas duomenų padalijimas.
Naudodami tą pačią stratifikacijos schemą visiems modeliams:
- sumažinate riziką, kad rezultatų skirtumai atsiras vien dėl skirtingų duomenų pasiskirstymų, o ne dėl realių modelių savybių;
- padarote eksperimentų rezultatus pakartojamus ir lengviau interpretuojamus komandos nariams ar užsakovams;
- galite drąsiau priimti sprendimus dėl modelio pasirinkimo, nes žinote, kad vertinimas atliktas sąžiningomis sąlygomis.
Stratified sampling ir kryžminė validacija
Kryžminė validacija (cross-validation) – tai dar vienas scenarijus, kuriame stratified sampling suvaidina itin svarbų vaidmenį. Naudojant stratified k-fold cross-validation metodą, kiekvienas foldas sudaromas taip, kad jame būtų išlaikytas klasių pasiskirstymas, panašus į visos populiacijos.
Tokio požiūrio privalumai:
- visi foldai tampa reprezentatyvūs, todėl modelio metrikos vidurkis ir dispersija geriau atspindi tikrąją jo kokybę;
- mažėja rizika, kad vienas iš foldų netyčia „praras“ retesnes klases ir sugadins bendrą įvertinimą;
- vertinimas tampa stabilesnis, ypač kai duomenų nėra labai daug.
Stratified sampling vieta duomenų apdorojimo pipeline
Duomenų apdorojimo procese stratified sampling neturėtų būti atsietas nuo kitų žingsnių, tokių kaip valymas, transformacijos, balansavimas ar požymių inžinerija. Svarbu nuspręsti, kuriame pipeline etape atlikti stratifikaciją, kad išvengtumėte informacijos nutekėjimo (data leakage) ir kitų problemų.
- Valymas ir bazinės transformacijos prieš dalijimą. Dažniausiai pirmiausia atliekamas bazinis duomenų valymas (trūkstamos reikšmės, neteisingi įrašai) ir tik tada dalijami duomenys.
- Sudėtingesnės transformacijos po dalijimo. Normalizacija, standartizacija, požymių atranka ar generavimas taip pat turi būti atliekami tik pagal treniravimo duomenis ir taikomi validacijos/testavimo rinkiniams, kad nebūtų nutekėjimo.
- Balansavimo technikos po stratifikacijos. Jei vėliau taikote oversampling ar undersampling, tai turėtų vykti tik treniravimo rinkinyje, jau po to, kai jis gautas stratifikuojant.
Apibendrinimas: kodėl verta naudoti stratified sampling?
Stratified sampling duomenų dalijime yra vienas paprasčiausių ir tuo pačiu galingiausių būdų pagerinti mašininio mokymosi modelių kokybę ir patikimumą. Jis padeda išlaikyti teisingą klasių ar kitų svarbių požymių pasiskirstymą visuose rinkiniuose, sumažina atsitiktinių svyravimų įtaką ir leidžia tiksliau įvertinti modelių rezultatus.
Naudojant šį metodą kaip standartinę praktikos dalį tiek train/test split, tiek kryžminės validacijos scenarijuose, gaunami stabilesni, labiau pasikartojami ir verslo požiūriu prasmingesni rezultatai. Todėl stratified sampling turėtų būti laikomas ne papildoma opcija, o numatytuoju pasirinkimu visose klasifikavimo užduotyse, kuriose rūpi sąžiningas ir tikslus modelių vertinimas.


