Modelio ir Duomenų Paralelizavimas Dirbtiniame Intelecte: Gilus Nėrimas į Mokymo Efektyvumą
Išsamus vadovas apie Duomenų Paralelizavimą ir Modelio Paralelizavimą (Data and Model Parallelism) dirbtiniame intelekte. Sužinokite, kaip šios technikos optimizuoja didelio masto AI modelių mokymą, spręsdamos atminties ir skaičiavimo laiko problemas.
Átrijo AI mokymo pagrindai
Didelių Dirbtinio Intelekto (AI) modelių, ypač giluminio mokymosi, mokymas tapo viena didžiausių skaičiavimo problemų pastaruoju metu. Eksponentiškai augant modelių dydžiams ir duomenų kiekiams, tradiciniai mokymo metodai, naudojant vieną centrinį procesorių (CPU) ar net vieną grafinį procesorių (GPU), tampa nepraktiški dėl atminties apribojimų ir per ilgo mokymo laiko. Štai čia atsiranda **paralelizavimo** technikos – **modelio paralelizavimas** ir **duomenų paralelizavimas**, kurios leidžia efektyviai paskirstyti skaičiavimo apkrovą keliems įrenginiams.
Šis straipsnis gilinasi šias dvi fundamentalias strategijas, palygina jų privalumus, trūkumus ir naudojimo scenarijus, siekiant maksimaliai padidinti AI modelių mokymo efektyvumą.
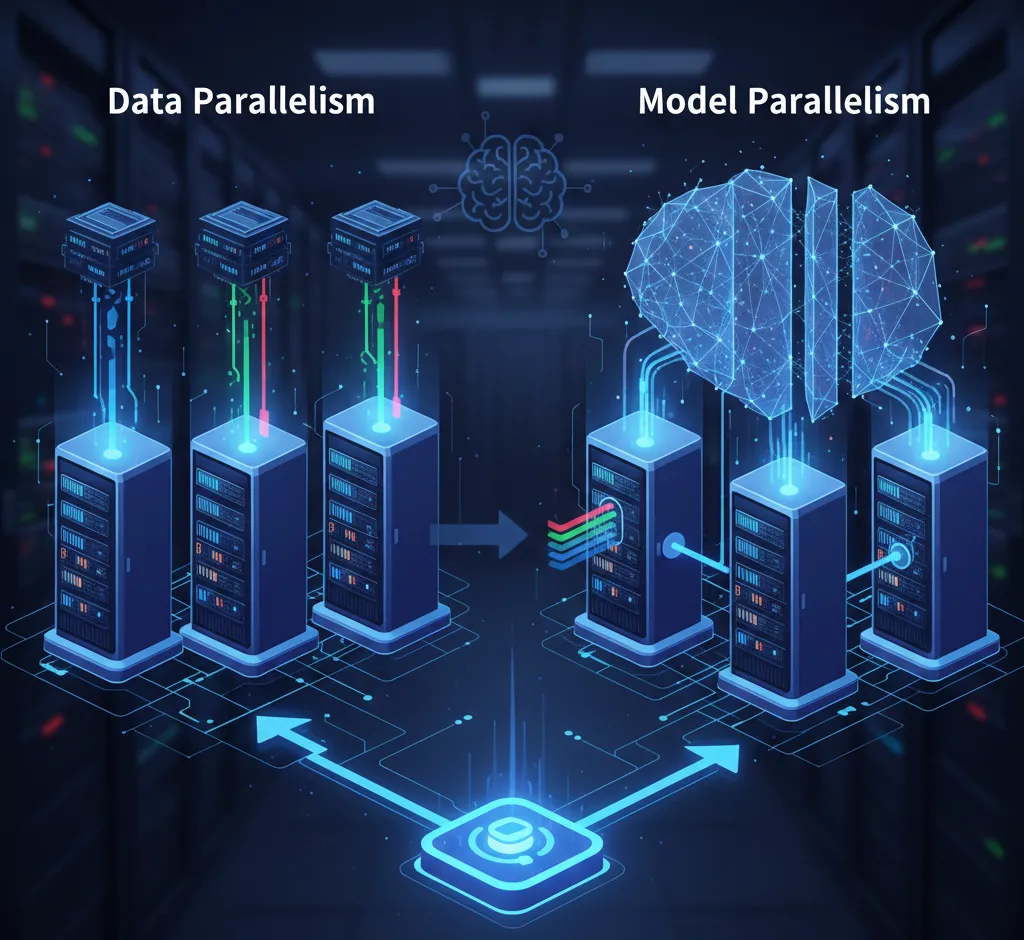
Duomenų Paralelizavimas (Data Parallelism)
Duomenų paralelizavimas yra labiausiai paplitusi ir lengviausiai įgyvendinama paralelizavimo forma, naudojama dirbtiniame intelekte. Ji puikiai tinka scenarijams, kai modelis lengvai telpa į vieno įrenginio (pvz., GPU) atmintį, bet duomenų rinkinys yra labai didelis.
Kaip tai veikia?
- Duomenų Paskirstymas: Mokymo duomenų rinkinys padalijamas į atskiras mažesnes dalis (mini-partijas). Kiekviena šių dalių yra atskirai apdorojama skirtingame skaičiavimo įrenginyje (GPU) arba mazge.
- Modelio Kopijos: Kiekvienas įrenginys turi identišką modelio kopiją.
- Apskaičiavimas: Kiekvienas GPU nepriklausomai apskaičiuoja gradiento nuokrypius, remdamasis tik savo duomenų mini-partija.
- Sinchronizavimas: Apskaičiuoti gradientai sujungiami ir sinchronizuojami per tinklą, o po to naudojami atnaujinti **pagrindiniam** (master) modelio svorių rinkiniui.
- Atnaujinimas: Atnaujinti svoriai siunčiami atgal visoms modelio kopijoms kito žingsnio pradžioje.
Svarbu paminėti, kad sinchronizacija gali būti atliekama sinchroniniu (visi laukia) arba asinchroniniu (kiekvienas atnaujinamas atskirai) būdu, priklausomai nuo reikalavimų.
Duomenų Paralelizavimo Privalumai:
- Paprastas įgyvendinimas: Lengvai pritaikomas egzistuojantiems modeliams.
- Greitas mokymas: Tiesiogiai proporcingas skaičiavimo įrenginių skaičiui.
Duomenų Paralelizavimo Trūkumai:
- Modelio Atminties Limitai: Neįveikia atminties limito problemos, jei pats modelis yra per didelis vienam GPU.
- Komunikacijos Sánaudos: Būtina nuolatinė ir didelė komunikacija gradientams keistis, kas gali tapti siauruoju butelio kakleliu dideliems klasteriams.
Modelio Paralelizavimas (Model Parallelism)
Modelio paralelizavimas naudojamas, kai pats AI modelis (jo sluoksniai ir/arba parametrai) yra toks didelis, kad netelpa į vieno įrenginio (GPU) atmintį. Jis yra žymiai sudėtingesnis už duomenų paralelizavimą.
Kaip tai veikia?
Vietoj to, kad būtų replikuojamas visas modelis, modelis **padalinamas į dalis** (sluoksnius, neuronų grupes, ar net atskiras matricas) ir šios dalys paskirstomos skirtingiems skaičiavimo įrenginiams.
- Sluoksnių Paskirstymas (Pipeline Parallelism): Modelis padalijamas seka. Pirmieji sluoksniai apdorojami viename GPU, viduriniai – kitame, ir paskutiniai – trečiame. Duomenys keliauja “konvejeriu” per šiuos GPU.
- Tarp Sluoksnių (Intra-Layer Parallelism): Sluoksnio skaičiavimai (pvz., didelė matricos daugyba) padalinami ir vykdomi lygiagrečiai per kelis GPU. Tai ypač aktualu transformatorių modeliuose, kur tam tikros operacijos yra itin didelės.
Modelio Paralelizavimo Privalumai:
- Didelio Masto Modeliai: Leidžia apmokyti modelius, kurių negalima apmokyti jokiu kitu būdu dėl atminties apribojimų.
- Efektyvus Atminties Panaudojimas: Maksimaliai išnaudojama visų įrenginių atmintis.
Modelio Paralelizavimo Trūkumai:
- Sudėtingas įgyvendinimas: Reikia sudėtingos komunikacijos logikos.
- Tuščioji Eiga (Bubble) Problem: Sluoksnių paskirstyme atsiranda laiko tarpai, kol konvejerio etapai užpildomi duomenimis (ypač pipeline atveju), kas sumažina efektyvumą.
Kada Kuriuo Naudotis?
- Naudokite Duomenų Paralelizavimą, kai: Modelis telpa į vieną GPU, bet turite **milžinišką duomenų rinkinį** ir norite greičiau atlikti iteracijas. Tai yra numatytasis pasirinkimas.
- Naudokite Modelio Paralelizavimą (arba hibridą), kai: Modelis **netelpa** į vieną GPU, neatsižvelgiant į duomenų rinkinio dydį (pvz., GPT-3, Megatron modeliai).
Daugelis modernių, didelio masto sistemų naudoja Hibridinį Paralelizavimą, kuris sujungia abi šias technikas. Pavyzdžiui, modelis gali būti padalintas (Modelio Paralelizavimas) per kelias GPU korteles viename mazge, o kiekvienas mazgas apdoros skirtingas duomenų partijas (Duomenų Paralelizavimas) iš bendro duomenų rinkinio. Tai leidžia maksimaliai išnaudoti tiek GPU atmintį, tiek bendrą skaičiavimo galią.
Modelio ir duomenų paralelizavimas yra kertiniai akmenys šiuolaikiniame dirbtinio intelekto inžinerijoje, leidžiantys mokyti vis sudėtingesnius ir galingesnius modelius. Teisingas šių technikų supratimas ir taikymas yra raktas į sėkmingą didelio masto AI projektų įgyvendinimą.


